Kronika snahy dostat blog zpět do indexu Google
Že Google svými úpravami začal likvidovat malé weby včetně toho mého jsem si povzdechl už v lednu při dvacetiletém výročí. Prokliky prakticky zmizely:

Web se vyhledat nedal a ze skoro čtyř tisíc stránek jich Google měl v indexu celých 95.
Tehdy jsem se nevzdal, začal hledat návody a informace, konzultoval to s několika umělými inteligencemi a vytipoval několik kroků, které jsem postupně zrealizoval.
A výsledek se dostavil! Počet zaindexovaných stránek spadl na krásných 6.
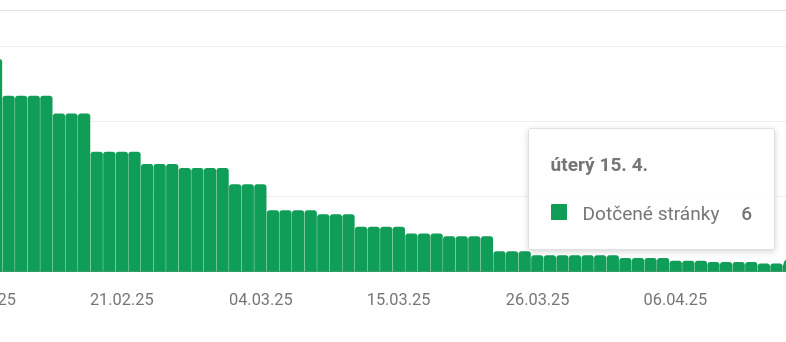
Ehm. Evidentně tedy důvod „Procházeno – momentálně neindexováno“, jehož zdrojem jsou „Systémy Google“, na formální změny obsahu moc nereaguje.

Ale pořád se odmítám smířit s tím, že by zápisník byl tak nekvalitní.
Leda že by moje používání označených citací z knih považoval za důvod neindexování, protože originál je jinde. To by bylo dost hloupé, když jde o citaci z knih a ne z webu… ale styl, jakým píšu, měnit nechci.
P. S. Čtěte až do konce, je tam dějový zvrat.
Co jsem tedy zkusil?
Odebrat starý tag meta robots, přidat link na canonical URL (13. 1. 2025)
V člácích jsem měl starý tag „meta robots“, sice se snažil říkat totéž co robots.txt, ale mohlo to být matoucí. Odebral jsem ho. A naopak jsem do článku přidal odkaz na kanonickou URL – protože je fakt, že na články (zejména komentářové) mohlo vést několik různě parametrizovaných odkazů. Kanonická URL ve všech variantách říká, která je správná a má se zaindexovat.
S obojím si Google odjakživa poradil, ale co kdyby. Vyžádal jsem reindexaci, která po pár dnech selhala, takže další krok…
Lepší meta description (15. 1. 2025)
Přeprogramoval jsem generátor blogu, aby se do description stránky namísto dosavadní kombinace „titulek článku + autor + datum“ použil první odstavec z textu článku.
Vyžádal jsem reindexaci, která po pár dnech selhala, takže…
Vytvořit sitemap.xml (19. 1. 2025)
K tomu mi na Mastodonu poradil „muž s klapkami na očích“ krásný skript, díky němuž si nad vygenerovanou verzí blogu vytvořím aktuální sitemapu a přidám do uploadu. Sitemapu jsem zmínil i v robots.txt a nastavil v Google Search konzoli, vyžádal reindexaci, která po pár dnech…
Chybějící H1 (3. 2. 2025)
V článcích používám jako podnadpisy až H4, vyšší nadpisy jsem měl v plánu. Předělal jsem tedy šablony, aby se na každé stránce použil titulek v H1 (akorát na indexu je v H1 jméno blogu a titulky článku jsou H2). Nezdá se to, ale bylo docela pracné to vychytat. Každopádně podařilo se, tedy jsem vyžádal reindexaci, která…
Změna chování www.blog.wuwej.net (8. 2. 2025, 28. 2. 2025)
K tomu mě vlastně přivedly Bing tools, které s www.blog.wuwej.net normálně operovaly. Z historie jsem věděl, že mě občas někdo z neznalosti zalinkoval s www. na začátku a že to fungovalo, ale vůbec jsem tomu nepřikládal váhu. Teď jsem tedy prověřil, jak se to u Wedosu chová a opravdu, sice nesedí certifikát, ale adresa se odroutuje na příslušnou doménu bez www.
Tady jsem si dělal velké naděje – protože jestliže pod www.blog.wuwej.net se vyskytuje stejný obsah jako pod blog.wuwej.net, mohl by ho celkem oprávněně google považovat za kopii a neindexovat. Založil jsem si tedy certifikát pro tuto doménu, přidal na ní permanentní redirekt na doménu bez www na všechno (301).
# Přesměrování www.blog.wuwj.net na blog.wuwej.net se zachováním cesty
RewriteCond %{HTTP_HOST} !^blog\.wuwej\.net$ [NC]
RewriteRule ^(.*)$ https://blog.wuwej.net/$1 [R=301,L]
Fakt jsem se těšil, že to zabere. Reindexace – ale ani po 20 dnech žádná změna.
Pak mě napadlo, že bych také mohl pustit reindexaci z té špatné domény www.blog.wuwej.net. Ale ani to nepomohlo.
Noindex *.php (16. 4.)
Ty komentářové stránky jsou si fakt podobné a je jich taky pár tisíc, možná že by ony mohly přispívat k vyřazování – tak jsem je všechny zakázal v robots.txt
User-agent: *
Allow: /
Disallow: /*.php$
Sitemap: https://blog.wuwej.net/sitemap.xml
Pustil reindexaci a vyčkával. Naděje jsem si už nedělal žádné.
Jen je paradoxní, jak se role otočily. Z Google je svévolný moloch, zatímco dřívější zlo Microsoft se s Bingem chová standardně.
Reupload adresy se sitemap.xml (18. 4.)
Sitemap jsem search konzoli nastavoval hned v lednu, ale všiml jsem si, že se k ní google moc nevrací. Tak jsem ji nastavil znovu.
Konečně obrat
- 16. 4. se počet zaindexovaných stránek zvedl o dvacet na 26.
- 20. 4. přibylo dalších 50, celkový počet 76.
- 21. 4. o den později se pod chybou „Procházeno – momentálně neindexováno – 4770 stránek“ objevilo „Objeveno – momentálně neindexováno – 1071“. Nepřibyly, ale buď konečně vzal sitemap na milost, nebo po změně robots.txt něco přehodnotil.
- 23. 4. zaindexovaných stránek 217.
- 27. 4. zaindexovaných stránek 491.
- 30. 4. zaindexovaných stránek 593.
- 4. 5. zaindexovaných stránek 636.
- 7.5. zaindexovaných stránek 661.
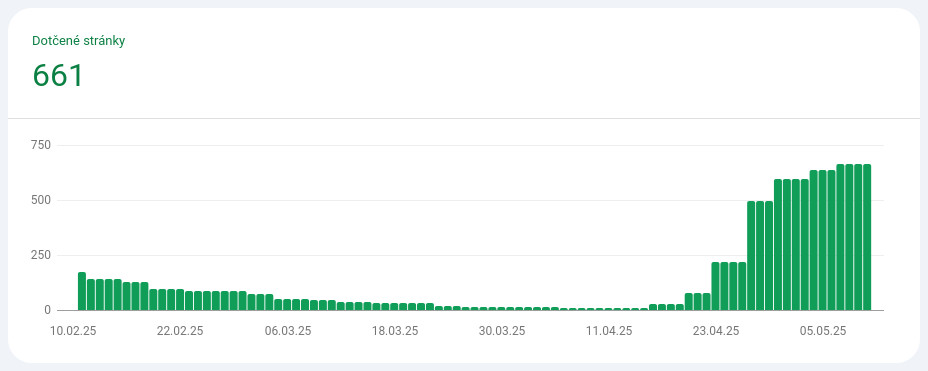
Nevím bohužel co přesně zabralo, pochybuju že to byly kroky z 16. 4., Google nereaguje okamžitě. Spíš něco z těch předchozích. Jo a už asi půl roku přidávám odkazy na články o knihách do sekce s recenzemi na obou knižních databázích, zatím jsem jich zvládl přes 600. Také to mohlo pomoci.
Každopádně – sláva!

Informace
Kontakt
- wu@wuwej.net
- Mastodon: @wuwej
Vyhledávání
Kategorie
- architektura
- citáty
- deník
- doprava
- duše
- ekonomie
- filozofie
- historie
- hudba
- knihy
- komiksy
- kultura
- labužník
- mastodon
- média
- nože
- o blogu
- od čtenáře
- odkazy
- politika
- počítače
- praktické
- produktivita
- příroda
- recyčlánky
- sociologie
- telefony
- tvorba
- výběr z blogu
- výběr z knih
- výzkumy
- věda
- čaj
- čeština
- školství
Archiv
- 2025
- 2024
- 2023
- 2022
- 2021
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- 2009
- 2008
- 2007
- 2006
- 2005


Hodnocení hvězdičkami používá jako prevenci
opakovaného kliknutí anonymní cookie.
Pokud s tím nesouhlasíte, neklikejte.
Další podrobnosti k cookies zde.